


Algorithms In The News = Not Good
It’s not likely to be ‘a good thing’ when the normally arcane world of algorithms, models & computer simulations make headline news.
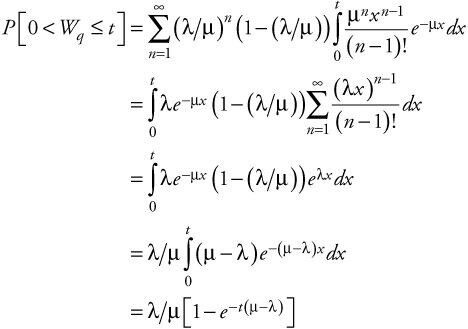
Models that do something useful will be left to quietly hum away and do their thing. Models that cause problems might make it into the news. Something in the world of algorithms must be going seriously wrong given the amount of coverage there’s been in the news recently.
First of all there was the covid modelling fiasco a few months ago, and more recently there’s the GCSE and A level results disaster.
Which got me thinking…computers, data, stats, models…that’s right up my street…I’ll write another article…especially as I can crowbar an alt-rock headline in there \~~/
Early 1980’s Home Computing
Like most gen Xers, my introduction to computers came about with the birth of home computing in the early 1980’s.
My super-geek younger brother Dave somehow got an Acorn Atom off the folks. I used to read code out of magazines for him to manually input, only for some terrible ‘game’ to take shape on the monitor.
Undeterred, Dave taught himself assembler at the age of 12 or 13 (no really!) and dragged our school almost single-handedly to the televised final of the national school computer quiz.
Unable to fathom out what on earth Dave was doing, I scratched my head in complete bewilderment and started going to rock gigs instead.
Leeds University & Real Computers

After obtaining the required A level grades – thankfully by examination not algorithm – I arrived at Leeds University in 1988 to study for a BSc in Geographical Science.
Quite early on we had to code in Pascal on a Unix mid-range system. This was quite a shock as I’d never yet understood, let alone mastered, anything to do with computers.
Essays, labs and coursework were hand-written in those days – there were no PCs, no internet, no email and no mobile phones. Just imagine!
Professor Mike Kirkby
Once the shock-horror of Pascal had subsided, things got a lot more interesting.
The ‘big cheese’ in the physical geography department was Professor Mike Kirkby.

As a bit of an Indiana Jones type character, Mike’s field trips to Spain were the highlight of the entire course for a lot of us, even if it was a tad chilly up the mountain in Spain, eh Carlo?
Mike was very fond of modelling. Even today, his bio contains the following words of wisdom:
“Models are generally seen as a thought experiments which are intended to demonstrate the consistency of general understanding, rather than as specific forecasting tools.”
Modelling The Watershed
Mike introduced us to the use of micro computers for modelling. Of particular interest was the Stanford Watershed Model. That’s all about rivers & streamflow, which allows the moody river Mersey photo below.

We spent many an hour coding, manipulating, testing & generally playing with said model. This all took place in the Leeds University computer lab resplendent with a fleet of 8 bit BBC Micro model B machines.
We’d moved on from Pascal to BBC Basic by now, with everything saved on a 5.25″ floppy disk.
Even though it is over 30 years ago, Mike’s lecture on the pros/cons of modelling has never left me. In particular, he emphasised the crucial role played by assumptions & constant values and their potential to have a significant, and sometimes disastrous, impact on outcomes. Wise words indeed.
So, in a few short years I’ve gone from being bedazzled by Dave and his Acorn Atom, having a stab at Pascal and being thrown in at the deep-end modelling streamflow in BBC Basic. Game on.
Gizza Job, I Can Do That *
As graduation loomed I headed over to the careers department to find out if my impending degree would help me land a job. With quite a bit of prodding from the careers person, I sat a computing aptitude test, scored well and applied for IT graduate trainee jobs.

After several interviews I landed a graduate trainee role at what was Royal Insurance (now RSA) back home in Liverpool.
The main requirement was to develop OLTP transactions and batch processing in Cobol on the IBM Mainframe.
After eventually mastering Cobol, I was moved onto the Management Information (MI) team after a couple of years.
Somewhat surprisingly, Royal Insurance were very early adopters of Teradata. This meant I had to learn SQL. Our trainer was none other than Brian Marshall who wrote the original Teradata books. He happened to be in the UK visiting relatives.
With a team of about 5 or 6 we built the ‘Household Information System’ (HIS) that contained all of the policies and claims for Royal’s entire household insurance book. The user interface was built using the Nomad 4GL. Those of us in IT used mainframe ITEQ and BTEQ.
According to Jim ‘the phone’ Clarke, the storm event models built using Teradata allowed ‘The Royal’ to recoup the £multi-million outlay on Teradata very quickly.
* A famous phrase at the time from Boys From The Black Stuff
California Dreaming
With a couple of years of new-fangled Teradata experience under my belt I started to get itchy feet. This was ’92 and there were not a lot of other jobs out there.

Luckily for me Bank of America in San Francisco were on the hunt for folks with Teradata and finance experience. By late ’92 I was California-bound . It took a while for my hang glider to arrive, but that’s another story.
Most of my time at ‘BofA’ was spent working in a business unit above the retail branch on the corner of Van Ness and Market St (on the right in the picture).
The main data centre and staff restaurant was next door at 1455 Market St (on the left in the picture). This is now home to the likes of Uber, Square and Vevo. How times have changed.
Branch Staffing Model
My role during most of ’93 was to write the specification for a branch staffing system.
This would use historic transaction volumes to predict the staffing requirement by hour for a year in advance across the entire BofA branch network. This was quite a sizeable estate given that BofA and Security Pacific (‘SecPac’) had just merged.

At the heart of the staffing model was a queuing algorithm. This was sent off to a maths professor at Berkeley to review. The only concern raised was that the queue of customers waiting to be served could grow exponentially if the model was wrong i.e. if there weren’t enough staff deployed to meet demand.
It was pointed out that few people join a queue once it gets above a certain length. Ivory tower meet real world.
Algorithms aside, the main challenge I faced was to write the 100 page spec using SGML on an IBM mainframe. How the algebra was expressed I have no idea. Forget PCs and word processors, there wasn’t even a print preview mode.
Sadly, I never did get to see the impact of the branch staffing project. After writing the spec I returned to Blighty. This was partly driven by Bay Area house prices which were even crazy in the early 90’s…at least compared to northern England!
Predictive Analytics
Upon returning to UK my main focus throughout the 90’s was Teradata, at places like Abbey National (now Santander), British Airways and TSB/LloydsTSB.

Throughout this period Teradata, and others, quite rightly talked about the business value of predicting ‘what will happen?’, rather than just rear-view reporting of ‘what happened?’ and ‘why did it happen?’.
Predictive analytics was the preserve of those who knew their way around tools such as SAS and SPSS. The key point here though is that using data to build predictive models is hardly a new endeavour. Anyone who was anyone with a data warehouse had an ‘ops research’ team.
The Rise Of Data Science
The last 10 years or so has seen the rise of ‘Big Data‘ and ‘Data Science‘, which is carried out, unsurprisingly, by ‘Data Scientists’.
Although Big Data and Data Science might mean slightly different things to different people, the role of the Data Scientist is even more debatable. Until a few years ago the job title itself didn’t even exist.
Teradata’s Stephen Brobst, who is always good for a one-liner, made us chuckle at one of the Teradata User Group (TUG) meetings when he opined that:
“A data scientist is an analyst that works in Silicon Valley”.
Martyn Jones further twists the knife in his book ‘Laughing @ Big Data‘:
“Without a grounding in statistics, a Data Scientist is a Data Lab Assistant”.
The folks that I’ve worked with over the years, such as Stuart Clarke, Rob Cooley, Ian Huston and Christian Setzkorn are, in my mind at least, ‘proper’ data scientists. The common thread is that they’re all maths boffins with a PhD.
For every Stuart, Rob, Ian or Christian there are probably another 50 analysts with no grounding in maths or stats that now call themselves Data Scientists. You know who you are.
Artificial Intelligence (AI) & Machine Learning (ML)

The latest data-related buzzwords are Artificial Intelligence (AI) & Machine Learning.
They both sound very cool and therefore must be useful, right?
Well, maybe. But as always, there’s nothing new under the sun.
Andriy Burkov’s most excellent Hundred Page Machine Learning Book gets right to it in the preface:
“…just like artificial intelligence is not intelligence, machine learning is not learning”
It’s Still Just Stats
No matter whether we call it predictive analytics, data science, machine learning or artificial intelligence, at the end of the day, inherently it’s still just stats.
Sir Ronald Aylmer Fisher is credited as the person who “single-handedly created the foundations for modern statistical science” and as “the single most important figure in 20th century statistics” – probably with 95% confidence.
A student of Fisher, George Box was hailed as “one of the great statistical minds of the 20th century“.
The aphorism that “all models are wrong” is generally attributed to Box. Yes, that’s what one of the greatest minds in modern stats is credited with saying, more than once:
“All models are wrong”.
Covid Modelling
Neil Ferguson’s modelling team at Imperial College London (ICL) would have done well to heed Box’s guidance from 1976:
“Since all models are wrong the scientist cannot obtain a ‘correct’ one by excessive elaboration…overelaboration and overparameterization is often the mark of mediocrity…the scientist must be alert to what is importantly wrong.”
And as taught by Mike Kirkby to yours truly (thanks Mike), Box also states:
“…parsimonious models often do provide remarkably useful approximations.”
But the ICL team didn’t follow such well-grounded guidance. They did the polar opposite.
They wrote tens of thousands of lines of undocumented, untested tombstone code over several decades. The non-peer reviewed results were then used to steer government covid policy in the UK and elsewhere.
No matter that they should be proud of their work, the flimsy excuses being used to justify not publishing the original modelling code are nothing short of scandalous.
The Lockdown Sceptics web site covers the covid modelling fiasco in detail:
The comments section on both articles above are a joy to behold and well worth an hour or two of anyone’s time.
Here’s what the geeks think of the massaged (i.e. not the original) code:
Non-functional requirements, coding standards, comments, unit testing, code review, QA, documentation, release to live, warranty & support. What quaint concepts!
A Level & GCSE Algorithm

Even more recently, algorithms are at the heart of the A level and GSCE results fiasco.
Cancelled exams, predicted grades, student rankings, normalisation algorithms, back to predicted grades…what an unholy mess.
After making such an unholy mess the exam boards and government between them have decided to either rely on predicted grades or pull the results altogether in the case of Btecs.
The Office for Statistics Regulation (OSR) is so critical of the algorithm used by Ofqual it has offered to conduct an urgent review.
So What’s The Message?
Well, firstly, as always, there’s “nowt new under the sun” (no matter what the Kool-aid crowd would have us believe). Stats has been around for a long time. No matter what new monikers we apply, it’s still ‘just stats’.
Secondly, statistical modelling is not an exact science, far from it.
Models should be kept as simple as possible and used as guidance, not a silver bullet:
“There are three kinds of lies: lies, damned lies, and statistics”
Where does this leave us?
Well, it’s been known for a long time that we simply can’t trust ‘the machine’.
Following the A level results fiasco, youngsters took to the streets to voice exactly that view, albeit in more straightforward terms, chanting “F*** the algorithm“.
Zack, Tom, Tim & Brad would no doubt concur.


